In the fast-paced world of cloud-native development, downtime isn’t just an inconvenience — it’s a blocker for teams and a risk for the business. That's why we're building OpsWorker.ai, your 24/7 AI SRE CoWorker, designed to autonomously detect, investigate, and resolve Kubernetes incidents — all while empowering developers and SRE Engineers with actionable insights and reducing operational toil.
Today, we’re excited to share the first live demo of OpsWorker.ai, the result of just 2 months of part-time work — and already, it’s fixing critical incidents and helping teams regain control over complex Kubernetes environments.
Live Demo: Real-Time Incident Response with OpsWorker.ai
For this demonstration, we use one of our testbed applications: Evershop, a Node.js e-commerce service backed by PostgreSQL on AWS RDS and deployed on Kubernetes. Like many production systems, it uses Deployments, Pods, ReplicaSets, Persistent Volumes, and an AWS Load Balancer Controller for ingress.
As luck (or reality) would have it — the worst issues tend to strike where it hurts most. In our case, the checkout page suddenly goes offline.
We simulate this by triggering an OOM (Out of Memory) condition via a purpose-built API endpoint that exhausts pod memory. Within seconds, the browser stalls — the request hangs, and the checkout page is inaccessible.
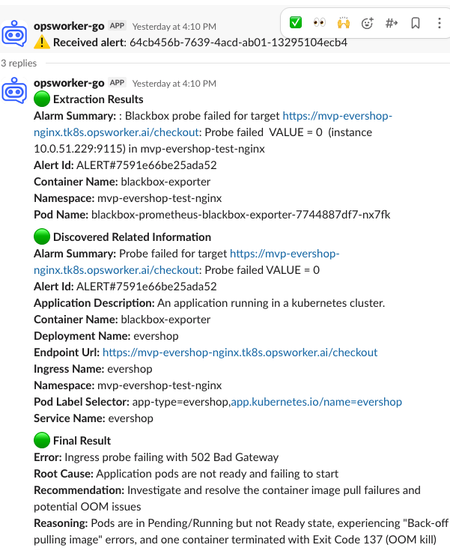
Behind the scenes, Prometheus detects the anomaly, and the Blackbox exporter fires an alert.
And that’s when OpsWorker.ai takes over.
⚙️ AI-Driven Root Cause Analysis in Action
OpsWorker is tightly integrated with alerting pipelines and communication tools like Slack (with a customer portal coming soon). The moment the alert fires, OpsWorker appears in Slack and starts its investigation.
This is no basic log scraper or shallow correlation tool. OpsWorker operates in phases, designed to ensure accuracy, depth, and zero hallucinations.
- Extraction Phase: OpsWorker links alerts to the correct Kubernetes objects — even when direct metadata is missing.
- Data Collection & Discovery: It fetches metrics, logs, and configuration data across pods, services, events, and workloads.
- Validation Checks: It examines object integrity and verifies deployment specifications, uncovering misconfigurations and human errors.
- AI-Powered Analysis: Combining observability data and configuration context, OpsWorker constructs a probable root cause — using enterprise-grade best practices as a baseline.
- Actionable Remediation: Finally, it summarizes the incident, pinpoints the root cause, and suggests clear, step-by-step remediation guidance.
🔍 Built for Real Incidents, Not Just Simulations
In our demo, OpsWorker correctly identifies the failing pod due to OOM, links it to the degraded service, and provides detailed remediation suggestions — all in under a minute. No need to hop between Grafana, Prometheus, kubectl.
What sets OpsWorker apart is its understanding of context and intent — not just metrics. It's not just a chatbot. It’s an AI that thinks like an SRE and acts like a senior engineer — with 24/7 availability.
🚀 What’s Next?
While OpsWorker is already showing promise in handling real incidents, this is just the beginning.
In the coming months, we’re focused on expanding its capabilities to address more complex, real-world challenges:
- Deeper Observability Integration: OpsWorker will support seamless integration with the most widely used observability tools — enabling richer context, more precise detection, and smarter investigation paths.
- Code & Release Awareness: We're working on enabling OpsWorker to analyze your code and recent release changes, helping teams pinpoint regressions or misconfigurations that may trigger incidents.
- Cloud Context Correlation: Future versions will integrate directly with major cloud providers, allowing OpsWorker to correlate cloud-level events — such as autoscaling, networking issues, or IAM policy changes — with Kubernetes workloads.
- Multi-Component Incident Handling: OpsWorker will evolve to manage more complex incidents involving multiple services, dependencies, and infrastructure layers — moving beyond single-service root cause analysis.
Our long-term goal is to make OpsWorker a truly autonomous teammate — one that not only resolves incidents but also prevents them supports development workflows, and continuously learns from your environment.
🤝 Try OpsWorker.ai
OpsWorker is currently in early access with select teams. If you're interested in redefining how your engineering org handles incidents — without burning out your team — get in touch with us or sign up for early access at opsworker.ai.
We believe the future of SRE is autonomous, context-aware, and developer-friendly. And we’re building that future — one resolved incident at a time.
Subscribe to our email newsletter and unlock access to members-only content and exclusive updates.
Comments