The modern approach to incident response is no longer gathering data — it’s understanding what happened.
A “single” alert in cloud-native systems often requires understanding application code, Kubernetes resources, traffic routing, and external dependencies. But most incident investigations today are still a process of engineers manually piecing together context across tools, frequently in the midst of an urgent situation and with incomplete information.
Which is exactly what OpsWorker Intelligent Investigation was created to resolve.
Instead of treating alerts as mere signals, OpsWorker will automatically conduct a full investigation for you; correlating alerts, validating infrastructure, tracing request path, pin-pointing the most probable root cause and suggesting real handling actions all in one normalized response.
Watch the video recording of the Product update
OpsWorker AI SRE Intelligent Investigation Product Video Presentation
What Is AI SRE Intelligent Investigation?
Intelligent Investigation is OpsWorker’s foundational feature around automated, explainable incident analysis.
When an alert arrives, the OpsWorker AI SRE Agent undertakes a multi-phased investigation which:
- Analyzes the context of the alert as well as its severity
- Discovers service and Kubernetes dependencies
- Validates infrastructure configuration and wiring
- The runtime is more interesting, and it will be able to do more and give an answer to the statistical distribution closure
- Correlates tested evidence into an understandable investigation conclusion
I don’t want to just say what happened, but why:
- Why it failed
- Why were other factors were not considered
- What should be done now
- What could have been done better to avoid reoccurrence
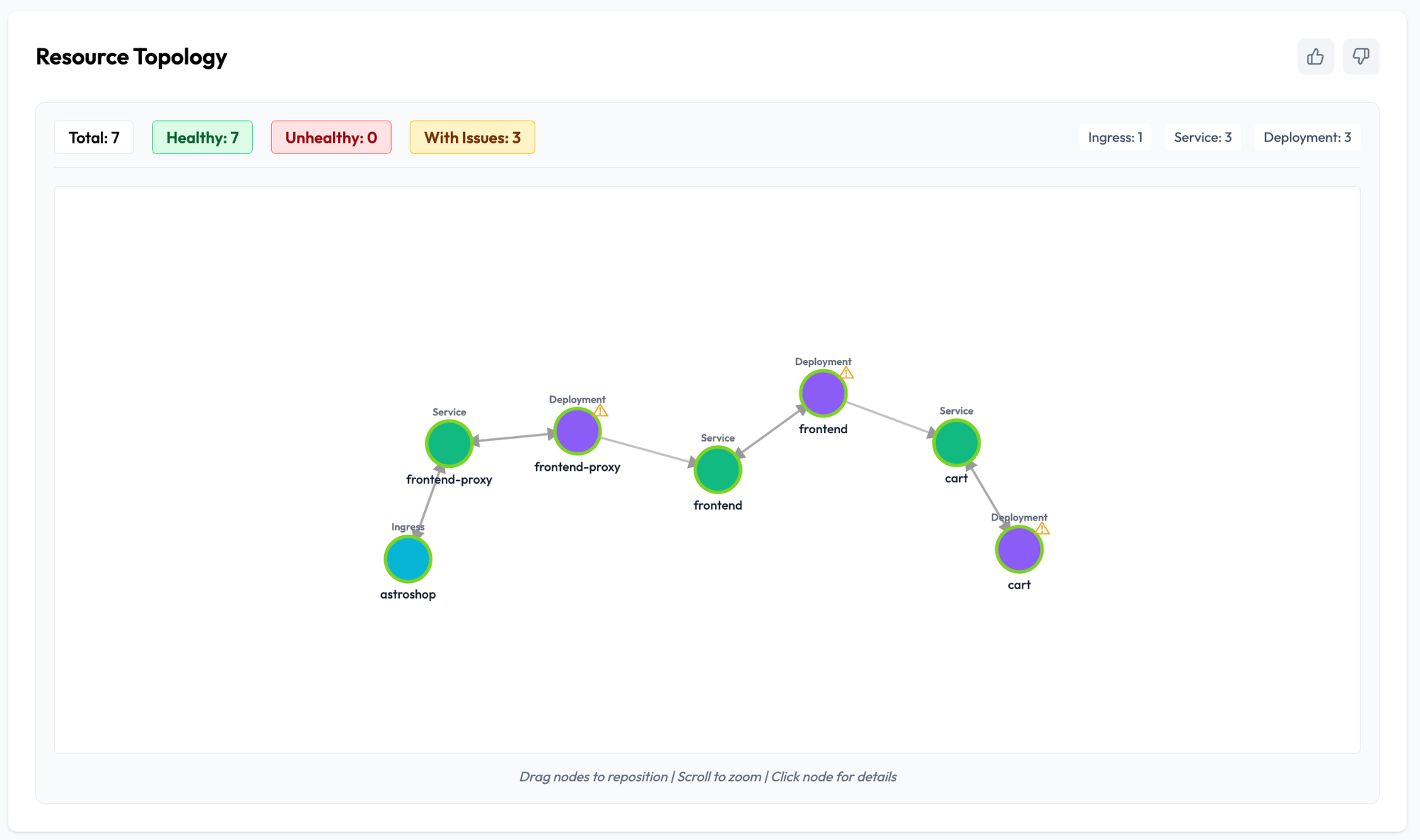
Topology of Resources — To Know How the Request Is Flowing
What It Does
OpsWorker rebuilds the request path throughout the system, which includes:
- External entry points
- Proxies and gateways
- Frontend services
- Backend services
- Stateful dependencies (e.g. data stores)
This defines how a request goes through the system and where things can fail.
Why It Matters
When the error happens (say, HTTP 5xx responses), teams usually find it challenging to diagnose exactly where in the chain the failure takes place.
Instead of relying on assumptions, OpsWorker AI SRE Agent verifies the full deps chain and reports back:
- Which components are involved
- Which components are healthy
- Where failures logically originate
This enables engineers to quickly focus on the right layer — application, dependency, or infrastructure.
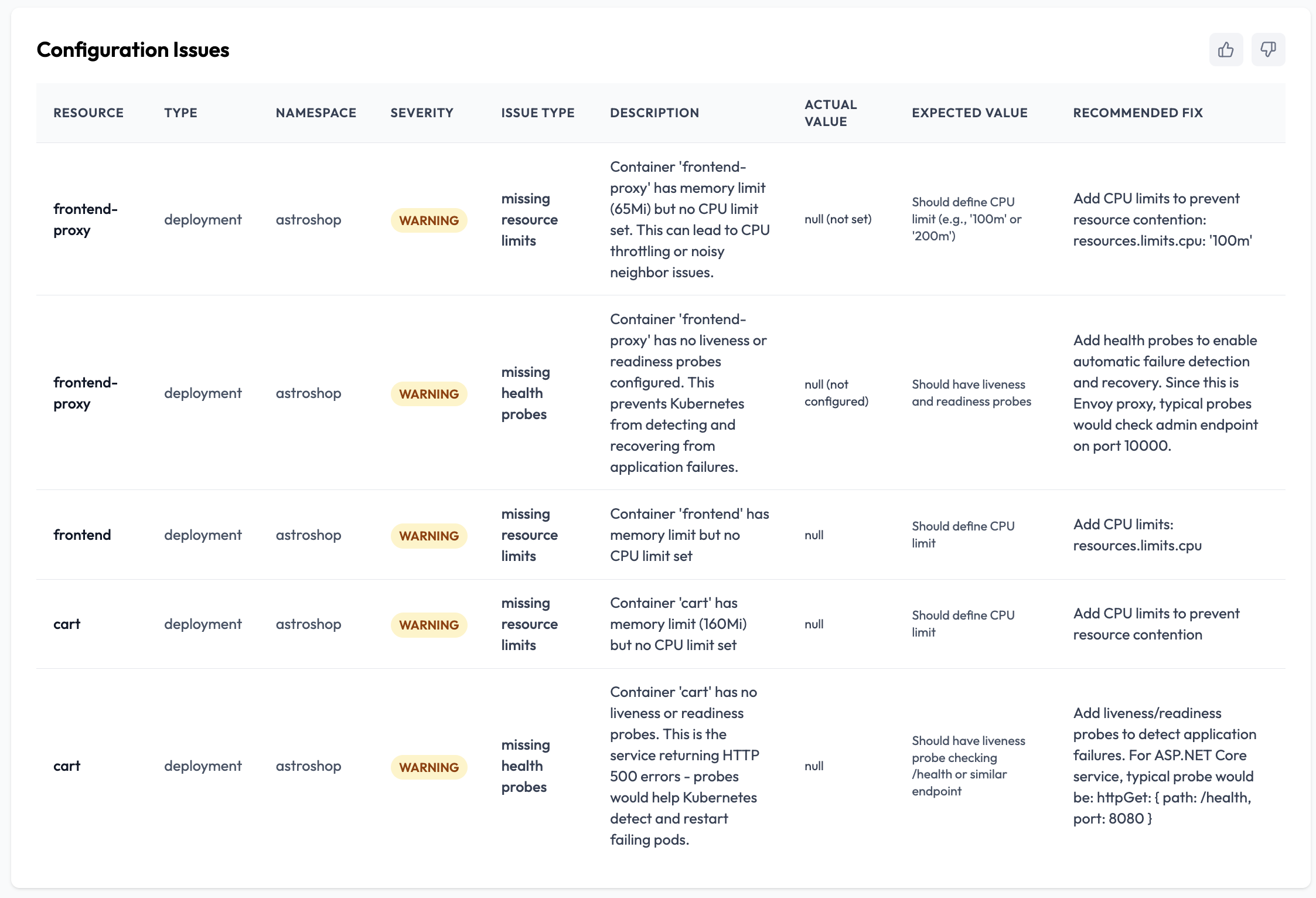
Configuration Issues: Validating the Foundation
What It Does
As part of that process OpsWorker validates configuration across the affected resources searching for common exploit by which a normal incident can be converted to something catastrophic:
- Missing CPU limits
- Missing liveness or readiness probes
- Unsafe or incomplete resource definitions
Each issue is assessed in context — not as a generic best practice violation but as a risk factor related to the particular event at hand.
Why It Matters
Misconfiguration alone is not responsible for a lot of these incidents but rather with configuration we constantly have:
- Prevent automatic recovery
- Increase blast radius
- Turn user-visible outages into transient failures
By detecting those blanks during the investigation, OpsWorker clarifies why the system did what it did and something to do about it.
Analysis Result: A Structured Explanation
What Intelligent Investigation Offers
It is a systematic investigation approach, based on the evidence not assumption.
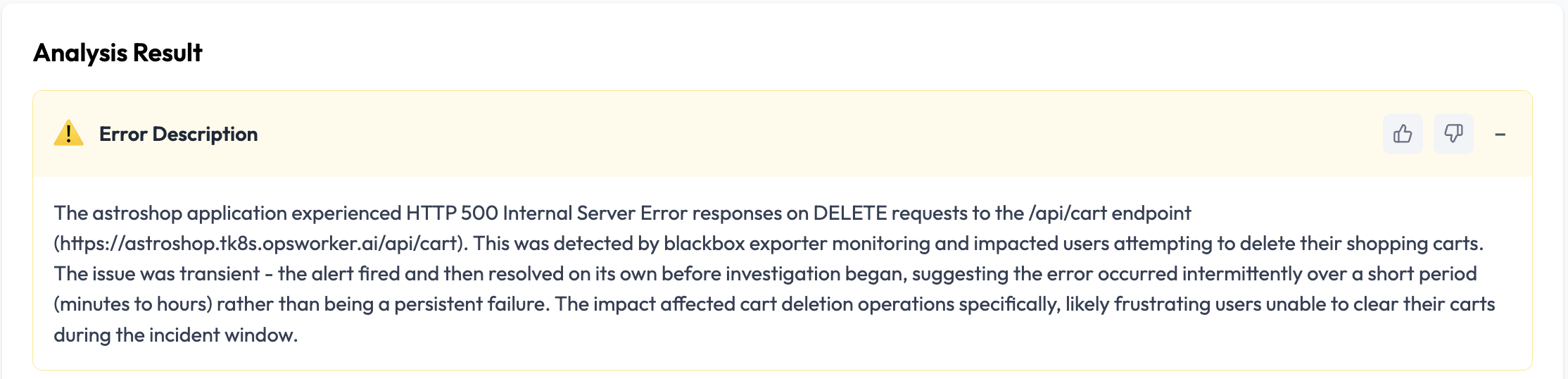
Error Description: What Happened
OpsWorker outputs a short, human-readable summary of failure to the file system containing:
- The affected operation
- The type of error observed
- The user-visible impact
Instead of using raw error codes, the description is what users saw and what functionality this affected, thus engineers are not left in the dark to try and determine by placing blame/helpers based on fault isolation.
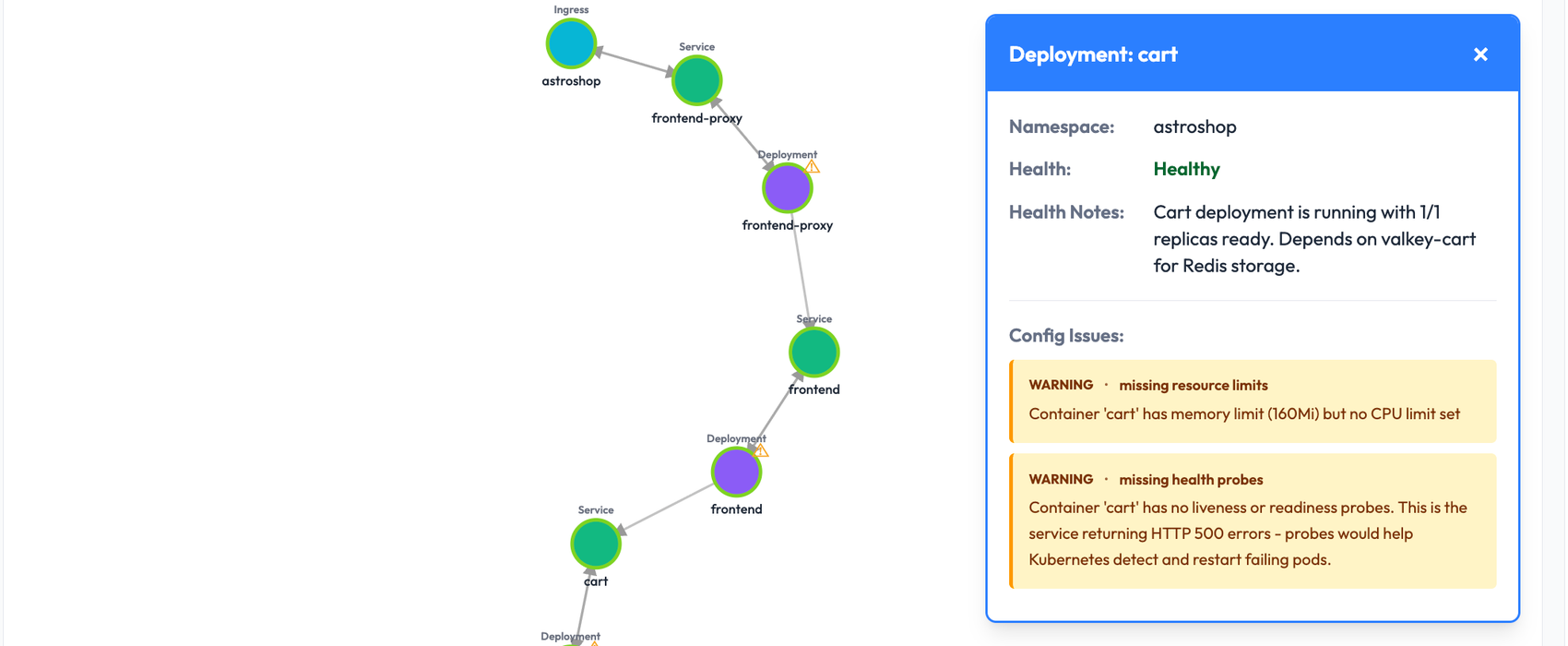
Root Cause: Why It Happened
OpsWorker AI SRE Agent correlates several independent signals and determines the most probable root cause such as:
- Patterns of the errors (e.g. http 500s vs gateway errors)
- Request flow analysis across services
- Dependency behavior
- Infrastructure validation results
- Time-domain characteristics (transient vs permanent failures)

The investigation, crucially, doesn’t just end at picking a cause — it is about explaining why you are saying that this cause fits the evidence and all other possibilities have been ruled out.
This also eliminates the guessing game of arguing over theories during incidents.
Contributing Factors: Why It Escalated
In addition to the root cause, OpsWorker analyses influencing elements that made the impact bigger or reduced resilience you can feel.
- Health probes missing causes Kubernetes from cleaning up unhealthy pods
- Inconsistent/faulty CPU limits with respect to resource allocations under load
- Low memory limiting dependencies more and more
- No circuit-breaker or retry in application code

And that is why the incident was user impacting, despite the fact that the failure that initiated it was transient.
AI SRE Immediate Actions: What to Do Right Now
During an event, teams require specific next steps, not abstract guidance.
OpsWorker recommends immediate steps to be taken based on:
- Stabilizing the system
- Enabling automatic recovery
- Reducing ongoing user impact

They specifically link to the underlying root cause and contributing factors, empowering teams to respond with confidence in the shortest possible time.
Preventive Measures: Eliminating Recurrence
Once the incident is contained, OpsWorker offers Preventive Measures to:
- Better handling of "transient" dependency failures
- Better error handling and retry mechanism
- Adding observability to critical operations

These suggestions support teams in transitioning from reactive bug fixes to lasting improvements, preventing the same failures sneaking back in.
Overall Improvements: Strengthening the System
Outside of the particular incident, OpsWorker emphasizes general improvements to the system such as:
- Including limits in order to not run into resource contention
- Adjusting resource sizing for predictability
- Introducing autoscaling or disruption budgets
- Increasing the availability for maintenance or load spikes
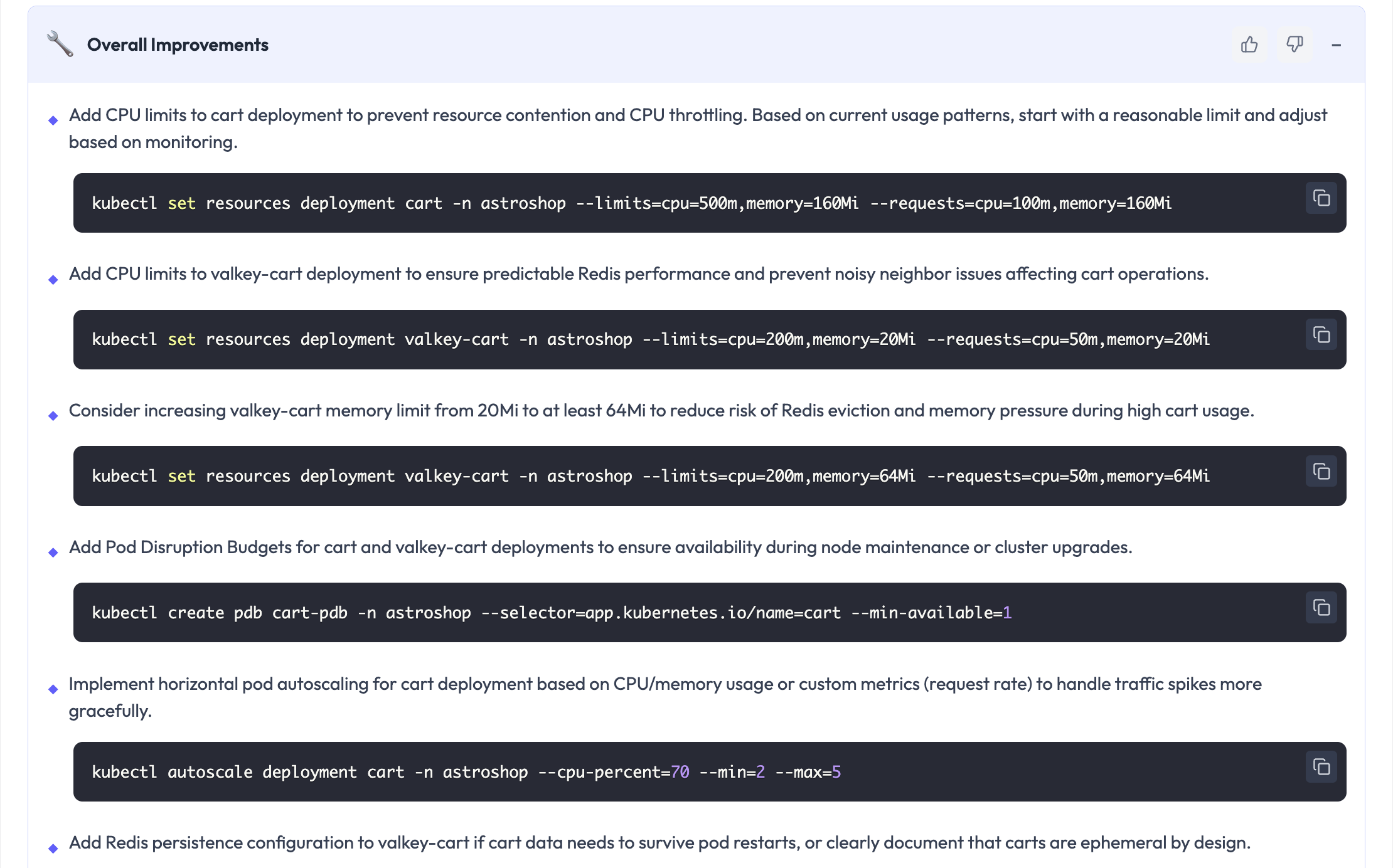
This makes each failure or outage an opportunity to raise the system’s baseline reliability.
Reasoning: Explainability Built In
Automation is only helpful when teams trust it.
Along with a Reasoning section that explains the:
- Which evidence was evaluated
- How conclusions were reached
- Why alternative explanations were rejected
- The confidence, the last assessment
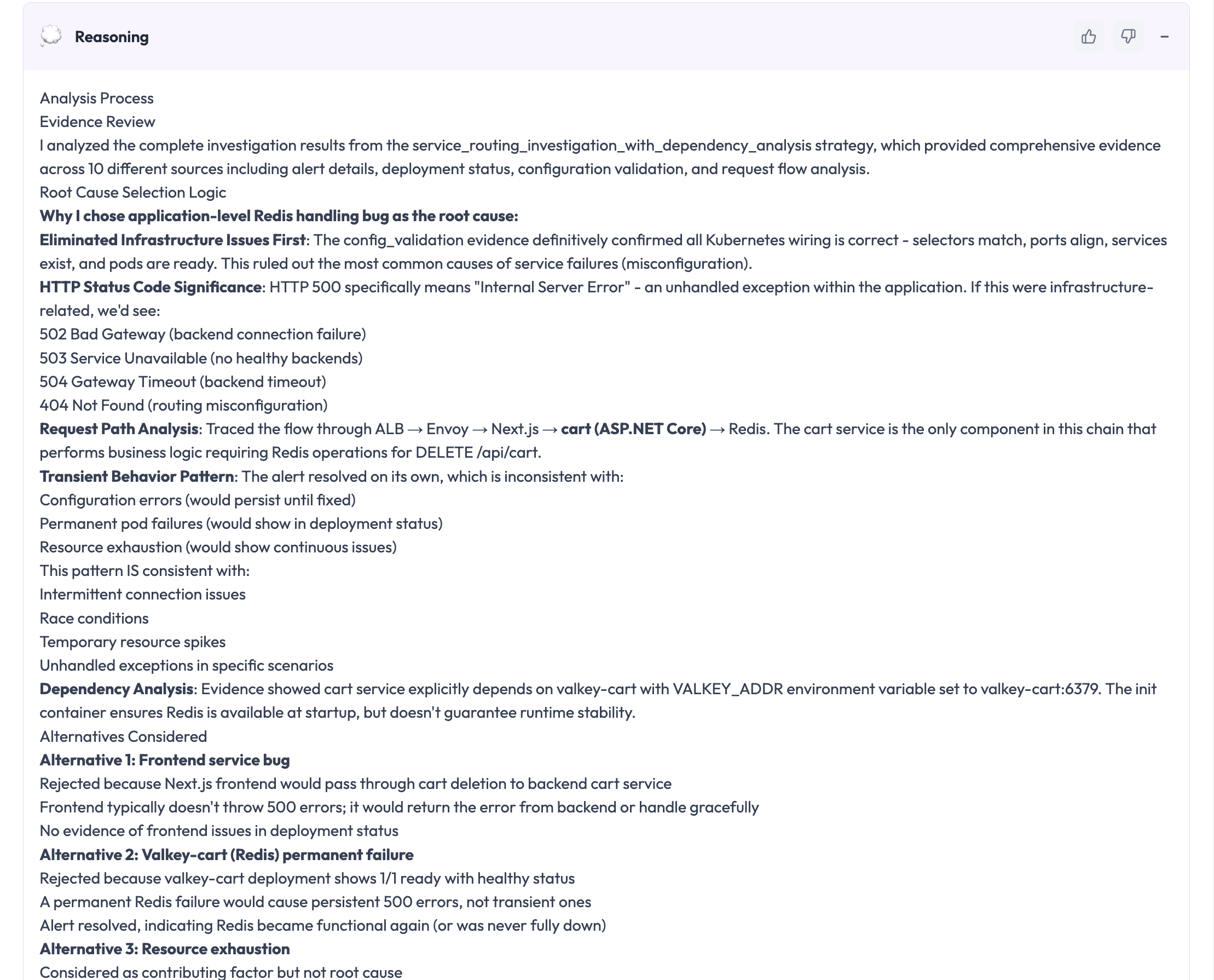
This is transparent, engineers can verify these actions and learn from the investigation of such incidents and build trust in automated analysis.
What values does OpsWorker AI SRE Intelligent investigations Agent provide to you as an end user
For SREs & On-Call Engineers
High Cognitive Load (Pain)
During our eight-hour on-call shift rotation, as many as 30–50% of our engineers’ time is spent watching systems, reading and responding to alerts, and maintaining a mental stack of known risks. For those occasions when incidents happen, they need to quickly gather context and align stakeholders while also investigating.
This cognitive burden leads to slower decisions and greater stress.
Faster Root Cause Identification (Value)
OpsWorker lays out the complete investigation easily:
- All checks performed
- The evidence on which psyche is built
- Crucial justification for the exclusion of other aetiologies
Engineers won’t have to piece the inquiry together themselves.
Lower MTTR (Outcome)
By auto-assembling context, teams go faster from alert to resolution, cutting downtime and on-call fatigue.
For Software Engineers
Production Complexity (Pain)
Typically developers are on the hook for production issues without in-depth infrastructure experience, and they need to grok Kubernetes in a hurry.
Clear Explanations (Value)
OpsWorker correlates application activity with infrastructure and dependency behavior, while keeping incidents accessible to everyone, regardless of their level of platform expertise.
Better Fixes (Outcome)
Developers target their fixes, fix root causes and lesson re-occurrences.
For Platform Teams
Repeated Patterns (Pain)
Platform teams see the same configuration and resilience issues turn up time after time post-incident.
Evidence-Based Improvements (Value)
OpsWorker links real incidents directly to configuration gaps, so that platform changes are clearly justifiable.
Fewer Incidents (Outcome)
Systematic enhancements decrease number of incidents and noise in the operation.
For CTOs & Engineering Leaders
Operational Drag (Pain)
Increasing MTTR, constrained senior SRE bandwidth, and growing burnout decrease the speed of delivery and increase risk.
Scalable Expertise (Value)
OpsWorker operationalizes senior-level investigative thinking into daily workflow, commoditizing expertise across the organization.
Healthier Teams (Outcome)
Faster recovery, less stress, and more time for engineers to actually build value.
From Alerts to Understanding
Intelligent Investigation transforms the nature of alerts.
Rather than causing panic and speculation, alerts are the entry point to immediate comprehension and informed decision.
It’s that switch — from reacting to explaining — that allows modern squads to handle complex systems, without driving the people who manage them to burnout.
Subscribe to our email newsletter and unlock access to members-only content and exclusive updates.
Comments