The landscape of AI Observability is shifting from simple alert monitoring to proactive, context-aware intelligence. At OpsWorker, we are committed to building the ultimate AI SRE—a digital teammate that doesn't just surface problems but understands your unique infrastructure.
Our latest release introduces significant advancements in AIOps, giving you more control over your AI stack, deeper Kubernetes integration, and a smarter way to manage alert fatigue.
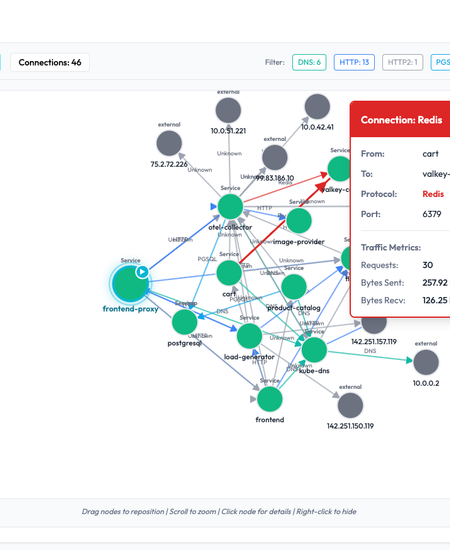
1. Visualizing the Web: Service Dependency Discovery
In complex microservices, the "root cause" is often three hops away from the initial alert. Our new experimental Service Dependency feature uses configuration analysis to map your cluster's internal relationships.
- Protocol Filtering: Isolate specific traffic types such as HTTP, DNS, PGSQL, or Redis to identify where connections are dropping.
- Infrastructure Topology: A clearer visualization of healthy vs. unhealthy objects helps you spot failing Ingresses or orphaned Deployments at a glance.
Enhanced Resource Topology & Service Discovery
We’ve introduced a clearer visualization for Kubernetes objects. You can now easily toggle between failing vs. running objects, including Ingresses and Service Endpoints.
Additionally, we are launching an experimental Service Dependency discovery feature. By analyzing your configurations, OpsWorker can now map out how services talk to each other (e.g., HTTP vs. PGSQL calls), making it easier to spot "broken links" in your microservices web.
- Filter by Protocol: Isolate HTTP, DNS, or Database calls.
- Root Cause Analysis: Get specific
kubectlcommands for primary fixes and preventive measures directly in the UI.
AI Observability service dependency map for Kubernetes microservices.
We’ve overhauled the investigation experience to make it more interactive and visual.
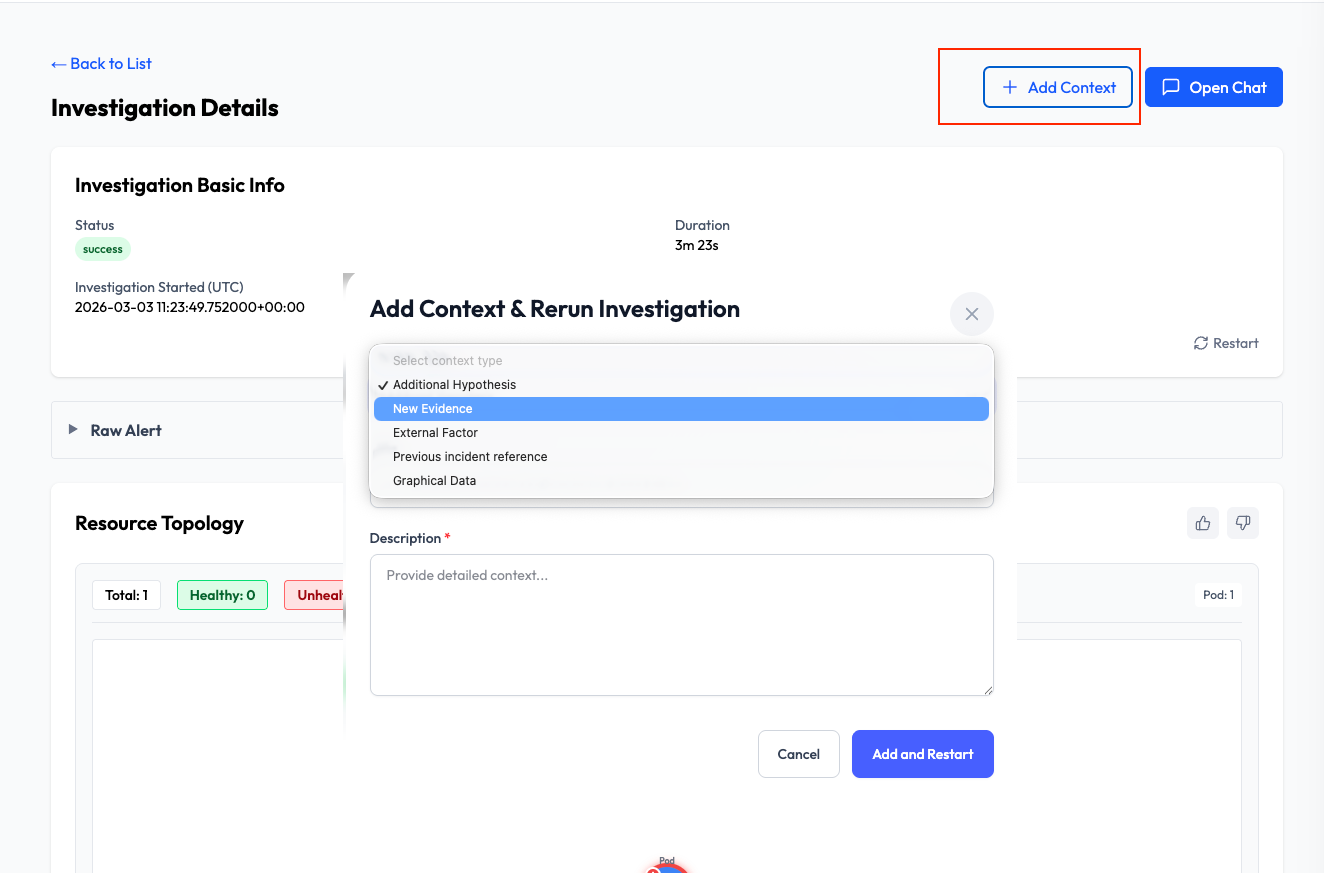
Add Custom Context & Rerun
Sometimes you have a piece of "tribal knowledge" or a specific log that the AI hasn't seen yet. You can now Add Context (such as an external factor or a previous incident reference) and rerun the investigation. This allows the AI to pivot its analysis based on your expert input.
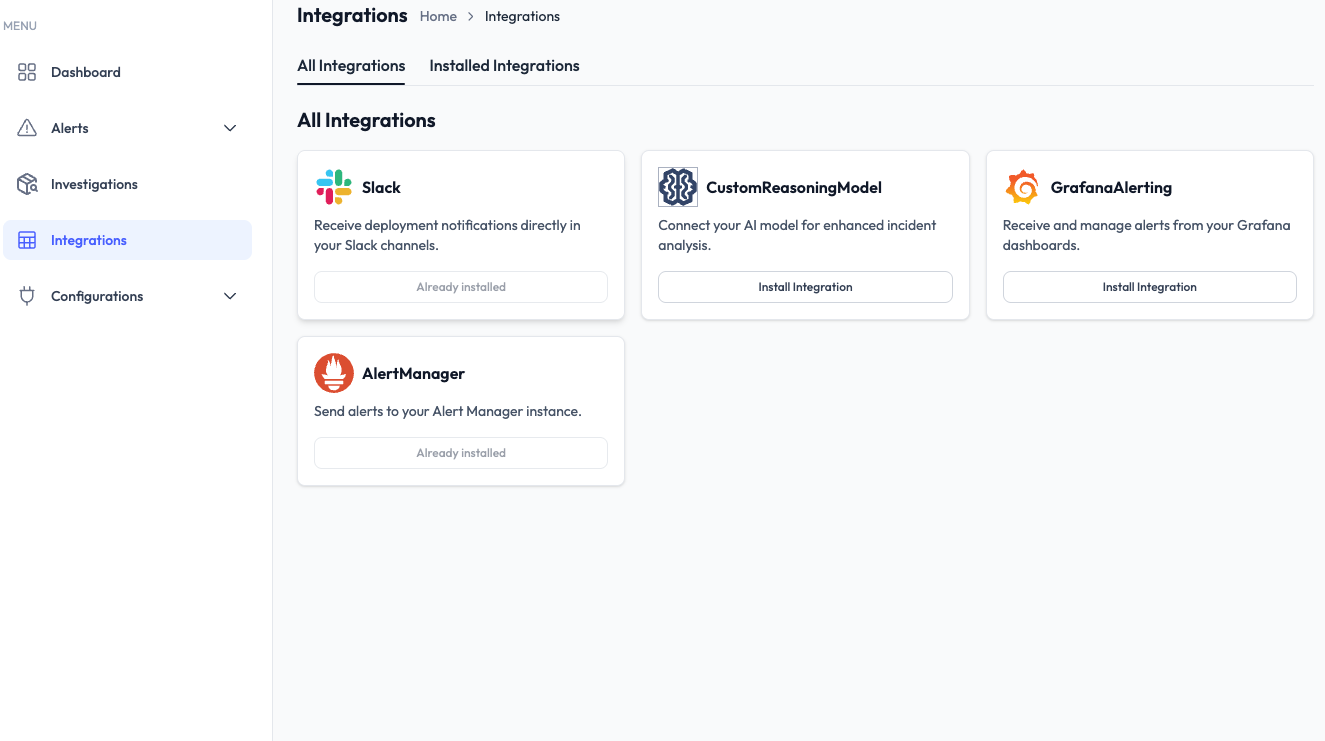
2. Governance Meets AIOps: Bring Your Own LLM (BYO LLM)
As organizations scale their AI Observability strategies, data sovereignty and model choice become critical. You can now connect your own LLM provider directly to OpsWorker.
- Custom AI Stack: Run investigation analysis using your preferred models (OpenAI, Anthropic, or internal deployments).
- Policy Compliance: Ensure all automated troubleshooting stays within your corporate AI and security boundaries.
- Grafana Alerting: We’ve added Grafana Alerting Contact Points, allowing your AI SRE to ingest and analyze signals from your existing Grafana dashboards instantly.
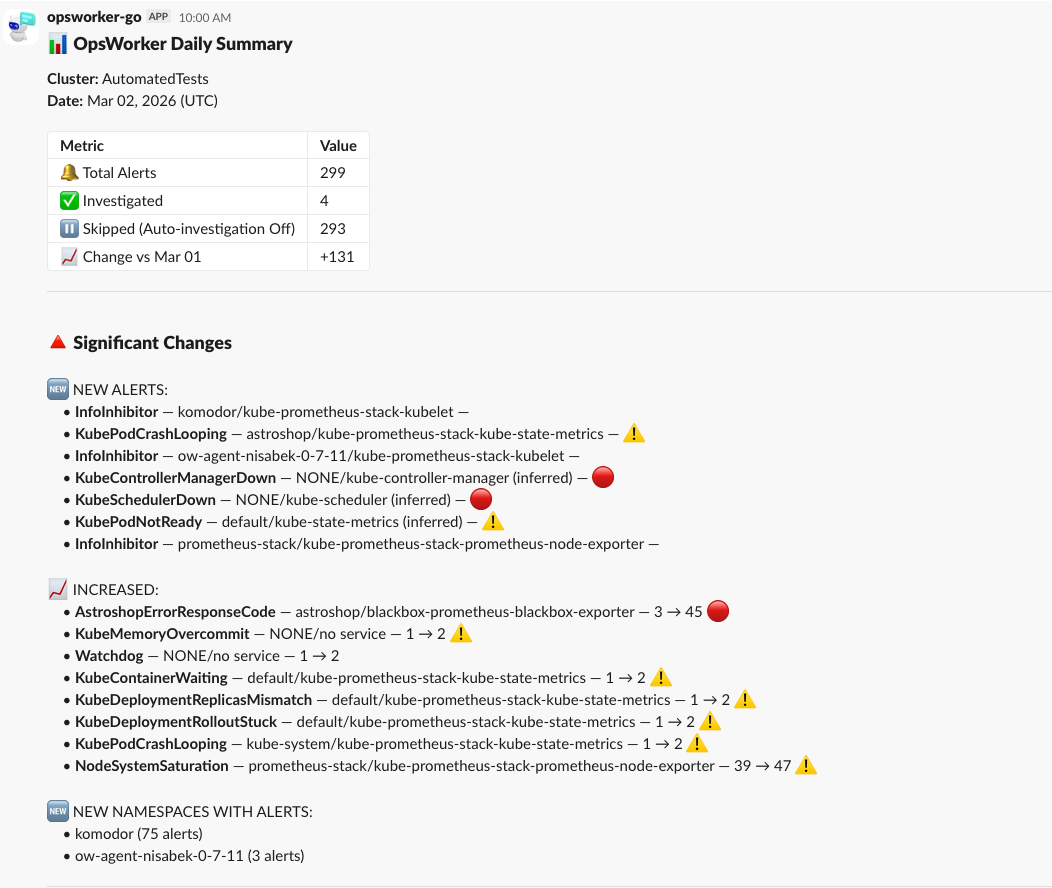
3. Eliminating Alert Fatigue: The Daily Diff Summary
A core challenge in AIOps is "noise." In high-velocity pre-production environments, traditional alerting can become overwhelming. Our new Daily Diff Summary for Slack transforms how SREs consume data.
Instead of a stream of repetitive alerts, OpsWorker provides a high-level "delta" of your cluster's health:
- Net Changes: See exactly what was created or resolved in the last 24 hours.
- Namespace Hotspots: Identify which parts of your cluster are becoming noisier (e.g., a 75-alert spike in the
komodornamespace). - Automated Insights: Track how many alerts were successfully investigated by the AI versus those skipped.
Tired of alert fatigue? Our new Daily Diff Summary for Slack is designed specifically for noisy pre-production environments or high-volume systems.
Instead of scanning a wall of text, you get a high-level breakdown of what actually changed—which alerts were created, which were resolved, and the "Top 7" namespaces by alert count. This helps your team focus on the delta after a release rather than the baseline noise.
| Key Benefit | How it helps |
| Noise Reduction | Highlights only the differences from the previous day. |
| Focus | Groups alerts by namespace and service to show impact areas. |
| Visibility | Tracks "Total Alerts" vs. "Investigated" to measure team coverage. |
4. Context-Aware Troubleshooting: MCP Agent & Custom Input
An AI SRE is only as good as the data it can access. We’ve introduced two major ways to deepen the context of your investigations:
Kubernetes API via MCP Agent
OpsWorker now utilizes a Model Context Protocol (MCP) agent to securely bridge the gap between your cluster and the AI.
- Real-Time State: The AI can now "see" the current state of pods, ingresses, and services.
- Security-First: The agent is read-only, ensuring that while the AI gets the context it needs, it never has the power to change your production environment.
Human-in-the-Loop: Add Context & Rerun
Incident response is a collaborative effort. If you have "tribal knowledge"—like a known external dependency issue or a specific log entry—you can now manually Add Context and trigger a rerun. This allows the AI to re-evaluate the root cause using your expert insights.
Ready to Scale Your AI Observability?
The era of the manual "on-call" rotation is evolving. By combining your expertise with OpsWorker’s AIOps engine, you can reduce Mean Time to Resolution (MTTR) and focus on building, not just fixing.
Subscribe to our email newsletter and unlock access to members-only content and exclusive updates.
Comments