Explore how agentic AI can autonomously process alerts, map dependencies, and resolve incidents across Kubernetes in real-world on-call scenarios
Modern on-call engineers operate in environments where a single alert often triggers a deep dive across services, systems, and cloud infrastructure. Diagnosing the root cause behind an HTTP 503 or a degraded service isn't a linear task — it involves reasoning across logs, metrics, dependencies, recent deployments, and misconfigurations.
Agentic AI offers a paradigm shift. Unlike traditional AI assistants, agentic systems think and act: they plan multi-step actions, query tools, correlate fragmented signals, and adapt as new data arrives. This article explores what that means in the real world, using a common scenario from Kubernetes operations to illustrate how agentic AI can autonomously process an alert, trace it to the right service, build a dependency map, and initiate diagnostic routines.
We’ll break down the architecture, challenges, and present a simplified multi-component pipeline to show how these systems are built.
Agentic AI Explained 🤖
Definition: Agentic AI refers to a system that can autonomously reason, plan multi-step actions, invoke external tools or APIs, and adapt its strategy based on evolving context and memory. It leverages LLMs not just for language output, but as a reasoning engine paired with tool-use capability.
Key attributes: For technical audiences, Agentic AI systems are characterized by chain-of-thought reasoning pipelines, modular tool invocation layers (e.g., API clients, kubectl operators), persistent scratchpad memory for intermediate results, context enrichment from multiple sources (logs, metrics, traces), and multi-turn orchestration logic.
Contrast with traditional AI assistants: Traditional AI assistants or chatbots provide stateless, single-shot responses based on surface-level prompt+response paradigms. Agentic AI systems in Kubernetes and cloud-native environments instead coordinate complex, multi-system workflows where resolving a single service issue (e.g., API downtime) often requires reasoning across heterogeneous data sources (Prometheus metrics, Kubernetes pod states, Istio traffic rules, RDS or DynamoDB health) and executing sequences of diagnostic or corrective actions.
From Alert to Action: Agentic AI Architectures for Incident Resolution ⚙️
Consider an on-call engineer who receives an alert from a BlackBox exporter via AlertManager(or any other alert with low context) about checkout service degradation
groups:
- name: blackbox-checkout-alerts
rules:
- alert: checkout page HTTP status code is not 200-399\n VALUE = 503\n (instance 10.0.44.151:9115)
expr: probe_success{job="blackbox", instance="https://checkout.example.com/health"} == 0
for: 1m
labels:
severity: critical
annotations:
summary: "Checkout service is unreachable"
description: "The Blackbox Exporter has failed to probe the checkout service at https://checkout.example.com/health for at least 1 minute."
As you can see from the alert, it’s not obvious which underlying downstream Kubernetes service, namespace, or pod is related to the endpoint. The agentic AI pipeline should kick in here: first ingesting the alert and identifying the endpoint’s relation to the underlying service. It maps ingress controller objects (e.g., Istio VirtualService, Nginx ingress) to the Kubernetes service behind the checkout page.
apiVersion: networking.istio.io/v1beta1
kind: VirtualService
metadata:
name: checkout
namespace: checkout-namespace
spec:
hosts:
- checkout.example.com
gateways:
- checkout-gateway
http:
- match:
- uri:
prefix: /checkout
route:
- destination:
host: checkout-service.checkout-namespace.svc.cluster.local
port:
number: 80
The next big complexity comes from discovering and resolving all dependencies between the endpoint service and the Kubernetes objects related to that service, especially if labeling has not been done correctly.
At this stage — where system complexity grows significantly — we map the full dependency graph of microservices tied to the checkout service, tracing not only direct and transitive service dependencies but also the databases and data stores those services rely on.
Now the Agents are ready to run a chain of pipelines to pull relevant logs, events, and metrics for each service, correlate recent deployments or config changes, and determine which downstream service or database is the likely root cause.
Additionally, to propose the correct intermediate or final remediation, tribal knowledge should be incorporated — sometimes at the beginning of the investigation, sometimes in the middle, or at the end.
And now imagine how much more complex this becomes when you want to make it generic for different types and sizes of customers with heterogeneous services, using different cloud providers and a wide range of technologies.
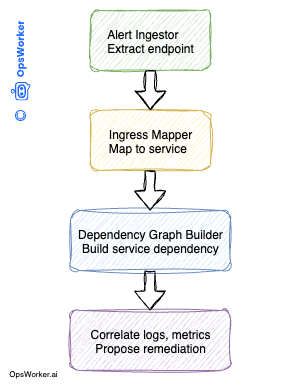
📌 Agentic AI Pipeline with Multi-Component Processing 💼
Agentic AI Pipeline with Multi-Component Processing for Checkout Service Incidents
In this section, we walk through a simplified code example demonstrating how an agentic AI architecture can process an incident alert for a checkout service using a Multi-Component Pipeline (MCP). The pipeline ingests an alert, maps it to the corresponding Kubernetes service via ingress objects, constructs a service dependency graph, and prepares the foundation for deeper investigations like log retrieval and root cause analysis.
The following Python-like pseudo-code illustrates how these components could interact:
from urllib.parse import urlparse
class AlertIngestor:
def __init__(self, alert_data: dict):
self.alert_data = alert_data
def extract_endpoint(self) -> str:
# Extract endpoint from Blackbox exporter alert
return self.alert_data.get("instance", "")
alert = {
"alertname": "CheckoutServiceDown",
"instance": "https://checkout.example.com/health",
"severity": "critical",
}
ingestor = AlertIngestor(alert)
endpoint = ingestor.extract_endpoint()
print(f"Received alert for endpoint: {endpoint}")
class IngressMapper:
def __init__(self):
self.virtual_services = {
"checkout.example.com": {
"namespace": "checkout-namespace",
"service": "checkout-service",
}
}
def map_endpoint(self, endpoint_url: str):
# Map by hostname; ignore path/query
if not endpoint_url:
return None
host = urlparse(endpoint_url).hostname
return self.virtual_services.get(host)
mapper = IngressMapper()
service_info = mapper.map_endpoint(endpoint)
print(f"Mapped to service: {service_info}")
class DependencyGraphBuilder:
def __init__(self):
self.dependencies = {
"checkout-service": ["payment-service", "cart-service", "user-db"]
}
def build_graph(self, service_name: str):
return self.dependencies.get(service_name, [])
graph_builder = DependencyGraphBuilder()
if service_info and "service" in service_info:
deps = graph_builder.build_graph(service_info["service"])
else:
deps = []
print(f"Dependencies: {deps}")
class AgenticPipeline:
def __init__(self, alert: dict):
self.alert = alert
def run(self):
endpoint = AlertIngestor(self.alert).extract_endpoint()
service_info = IngressMapper().map_endpoint(endpoint)
if not service_info or "service" not in service_info:
print("No mapping found for endpoint; stopping.")
return
deps = DependencyGraphBuilder().build_graph(service_info["service"])
print(f"Alert: {self.alert.get('alertname')}")
print(f"Endpoint: {endpoint}")
print(f"Service: {service_info}")
print(f"Dependencies: {deps}")
pipeline = AgenticPipeline(alert)
pipeline.run()
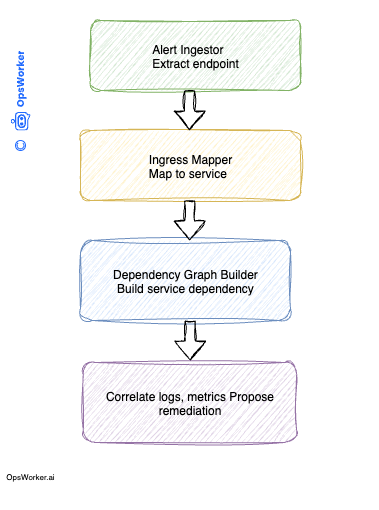
Let's put all together
Conclusion
As systems scale and incident complexity grows, agentic AI becomes not just useful, but essential. A surface-level alert like “checkout service unreachable” hides a cascade of possible causes: traffic misroutes, failing pods, slow databases, misconfigured Istio rules, or even a recent deployment.
The example architecture in this article demonstrates how an agentic AI system can take a loosely defined signal, navigate through Kubernetes abstractions and service dependencies, and begin a meaningful investigation — automatically.
While this pipeline is a simplified illustration, the real-world application involves integrating across diverse observability tools, cloud APIs, source control systems, and internal knowledge — all in a way that respects organizational context and security boundaries.
Agentic AI doesn’t replace engineers — it amplifies them. By handling the initial layers of investigation, correlation, and hypothesis-building, it gives teams the clarity and time they need to focus on higher-order problems.
The future of on-call engineering isn't just faster alerts — it's AI that understands what to do next.
Subscribe to our email newsletter and unlock access to members-only content and exclusive updates.
Comments