Modern systems can scale faster than teams ever could.
Microservices, Kubernetes, managed cloud services, and shared infrastructure have made software delivery more powerful — but also dramatically more complex. When something goes wrong in production, discovering the root cause of an incident across dozens of interdependent services still takes way too long.
For a mid-sized organization, this can translate into hundreds of incidents a year. They all sap attention, consume engineering time, and add operational risk.
Given that we’ve built ever more powerful observability stacks, incident investigation today is still largely manual:
- Engineers flip between dashboards, logs, and configurations
- Context is fractured across tools and teams
- Alerts tell us something is broken — but not why
And yet, the same preventable issues keep coming back.
That’s the gap OpsWorker was designed to fill.
Over the past two months, we’ve been single-minded about one thing:
Take the human guesswork out of incident investigation — and let machines do what they’re good at: understanding complex systems automatically.
Beginning next week, we’ll be publishing four key updates, packaged and designed to work together as an AI SRE Agent that drives faster incident investigation, lower MTTR, and reduced operational toil.
Why We’re Still Investigating Incidents Wrong
Cloud-native systems didn’t just add scale — they multiplied complexity.
Today:
- Mean MTTR ranges from 1 to 48 hours, depending on incident complexity
- 70–80% of incidents are repetitive L1/L2 activities
- Engineers lose 100–200 hours per year to reactive toil, maintaining the status quo
- Hidden operational cost equals roughly 1 additional FTE per 10 engineers
- Mid-sized SaaS companies lose $100k–$500k+ per hour of downtime, depending on impact
Alert fatigue, endless Dev ↔ Ops hand-offs, and mental graph traversal under pressure are not signs of bad teams — they are symptoms of systems operating beyond human scale.
As senior SRE talent becomes harder to hire, pressure increases, burnout risk grows, and incident response becomes even more fragile.
The 4×4 Update: What’s Coming Next Week
Starting next week, we’ll be announcing four core updates over four days — each addressing a critical failure point in modern incident workflows.
Day 1 — Intelligent Investigation
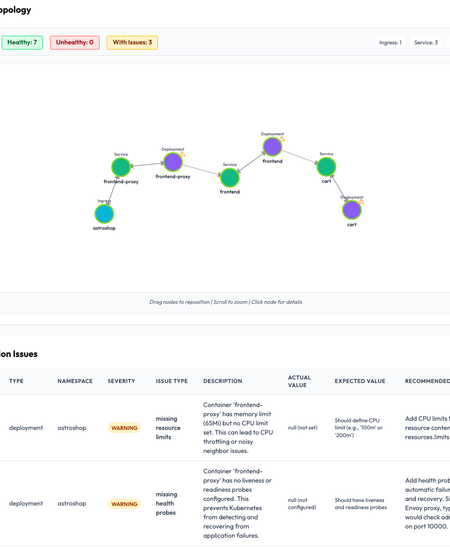
OpsWorker automatically parses alerts, discovers Kubernetes and service relationships, validates configurations, and generates structured incident investigations:
- Resource topology
- Error description
- Root cause
- Contributing factors
- Immediate actions
- Preventive measures
- Transparent reasoning
This replaces manual incident reconstruction with a clear, evidence-based understanding.

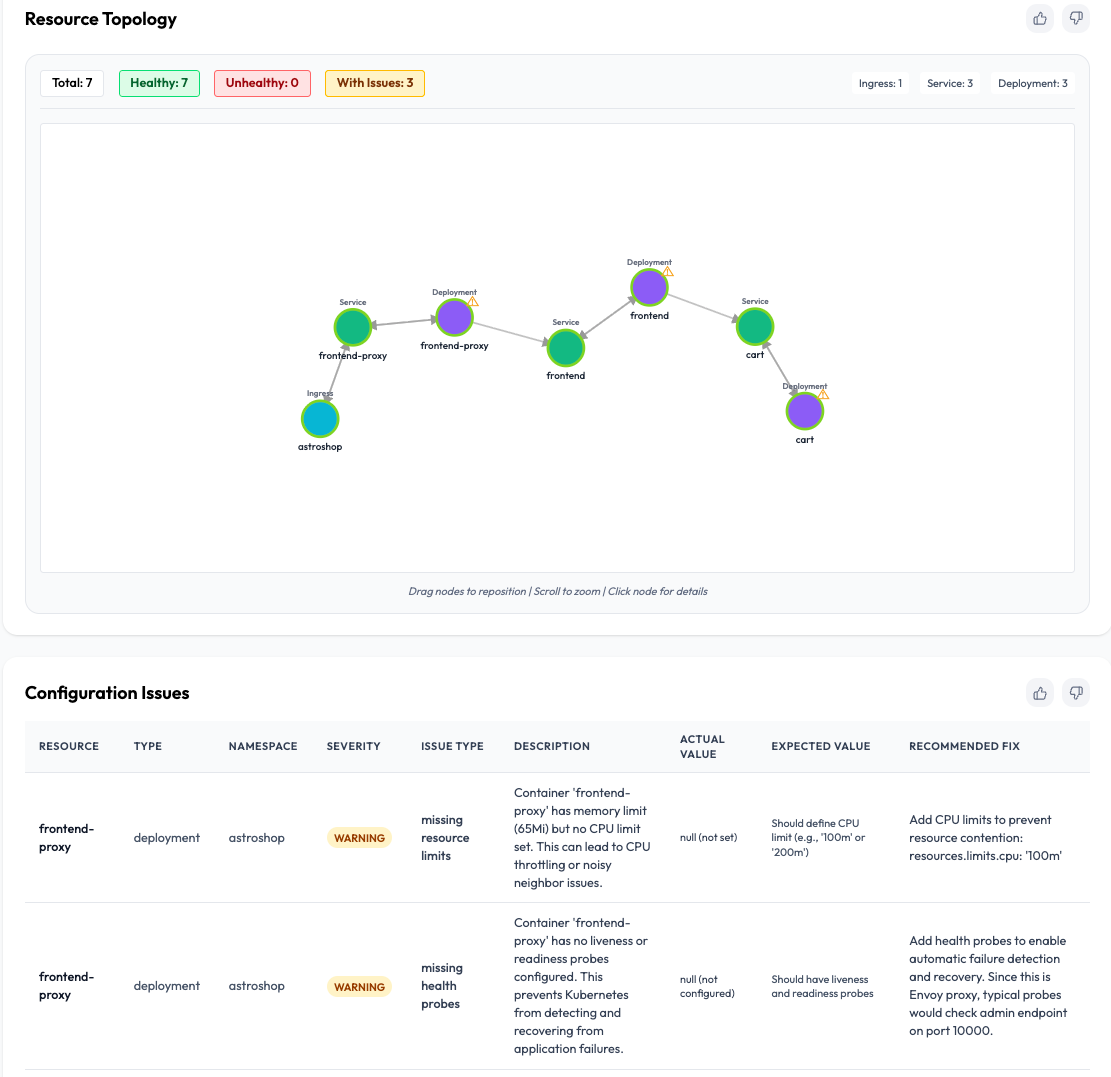

OpsWorker automatically parses alerts, discovers Kubernetes and service relationships, validates configurations, and generates structured incident investigations:
- Resource topology
- Error description
- Likely root cause
- Contributing factors
- Immediate actions
- Preventive measures
- Transparent reasoning
This replaces manual incident reconstruction with clear, evidence-based understanding.
Day 2 — Speak to the Investigation & Your Resources
Engineers can interact directly with the investigation:
- Ask follow-up questions
- Explore alternative root causes
- Add context
- Learn from real incidents
This transforms incidents into learning moments, not just fire drills — especially for teams that own the full lifecycle from code to production.
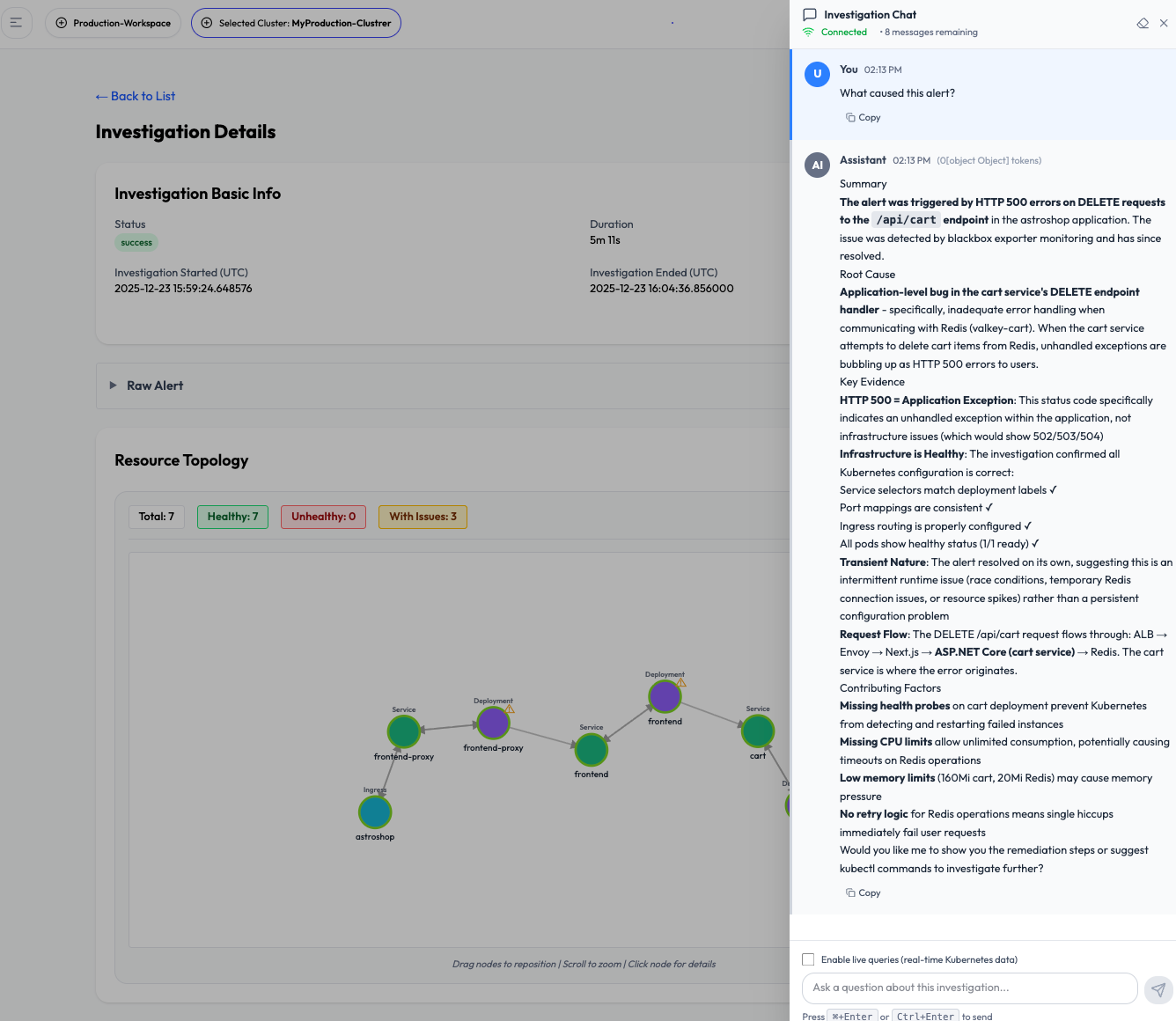
Day 3 — Smart Slack
Alerts shouldn’t require a PhD in dashboards.
Smart Slack delivers:
- Human-readable alert descriptions
- Explicit impact categorization (user-facing, internal, platform)
- Root cause findings
- Key evidence
- Immediate, copy-paste-ready actions
- Escalation signals when needed
Incident investigation begins — and often ends — inside Slack.
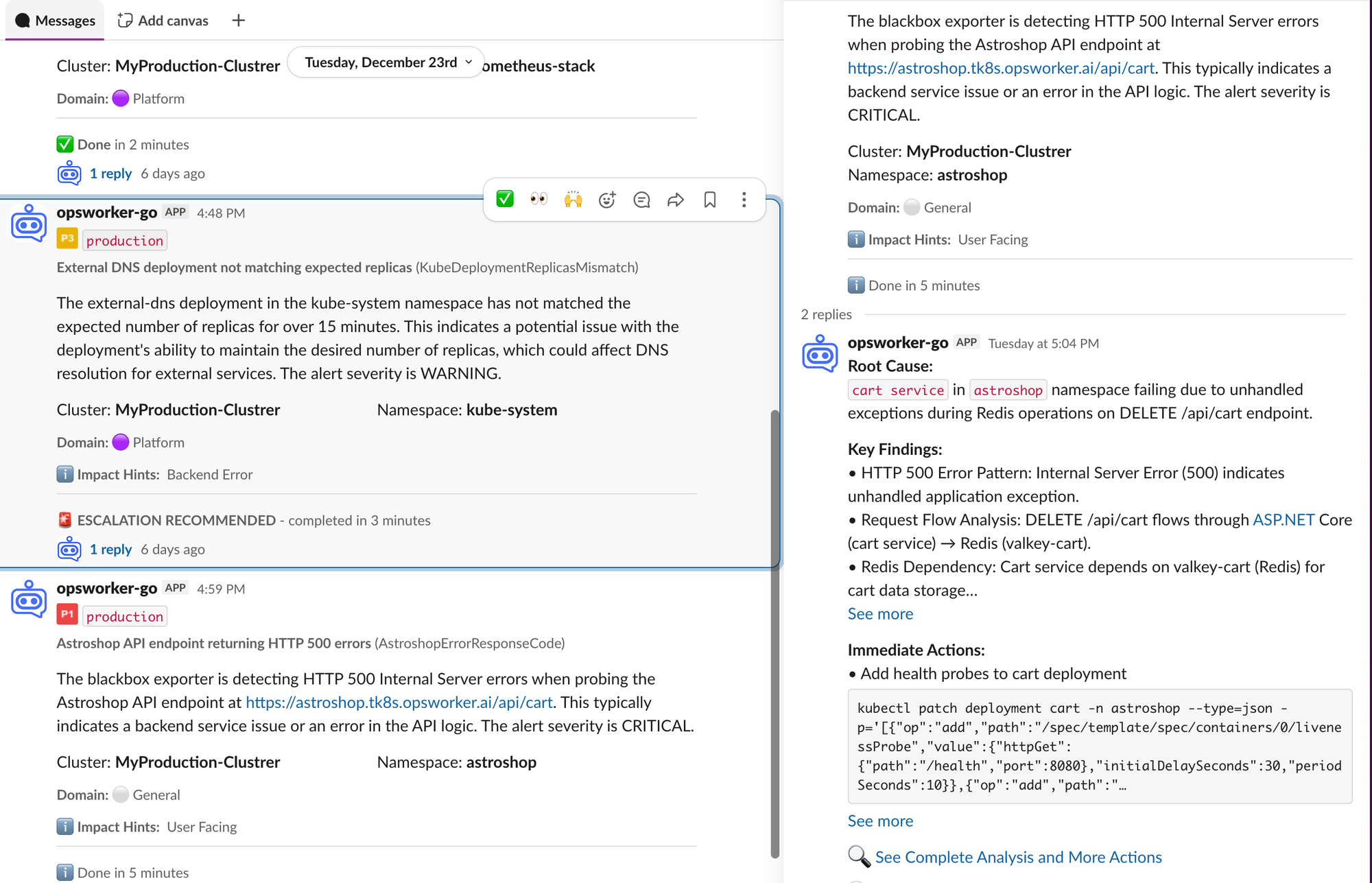
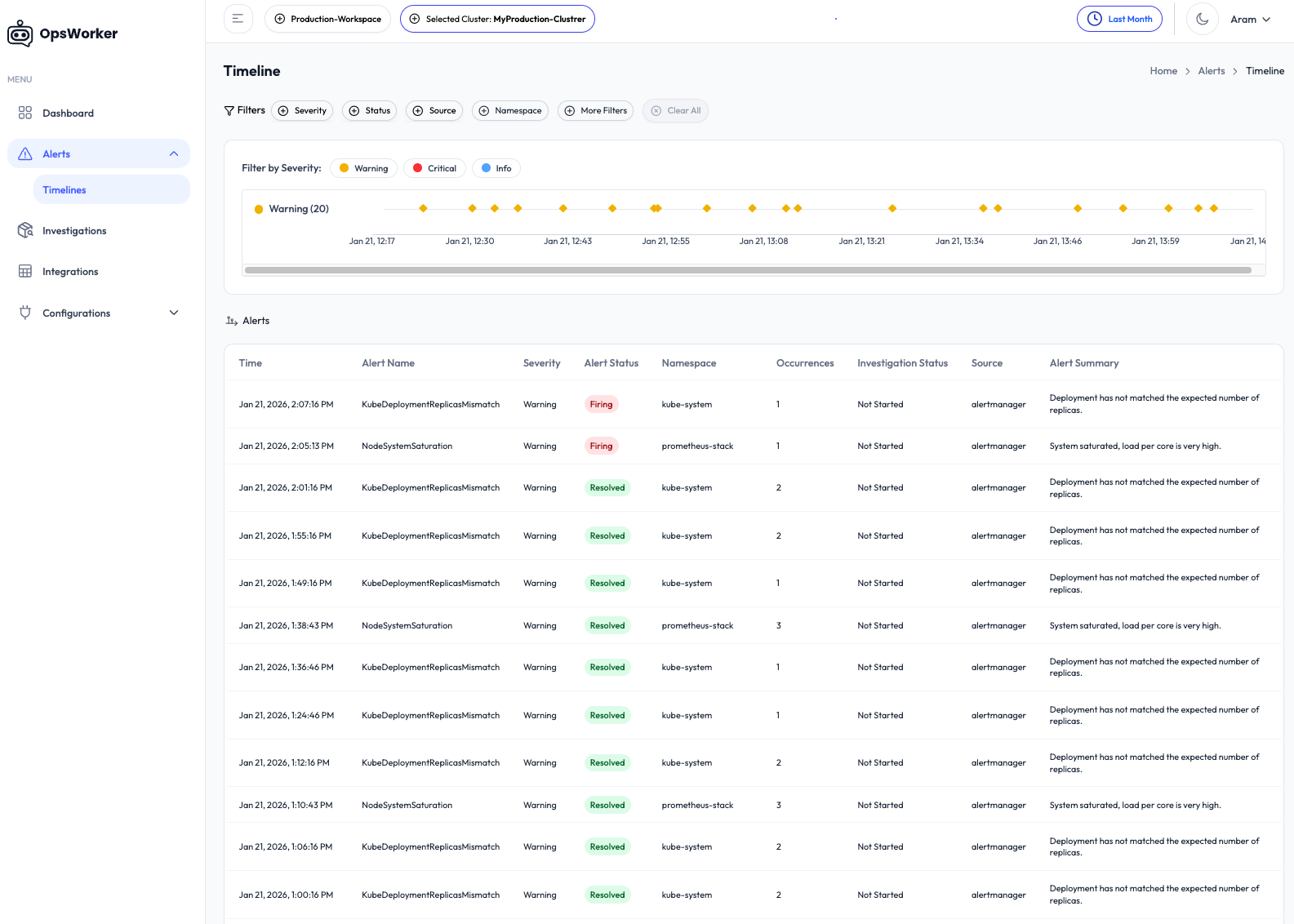
Day 4 — Enhanced Alerts View
A new alerts experience allows teams to:
- Filter and investigate alerts across environments
- Understand impact domains and severity
- Launch investigations directly from alerts
Detection and investigation finally become one continuous workflow.
Who This Is Built For
These updates are designed to support real-world incident work across the organization:
- SREs & On-call Engineers
Faster investigations, lower cognitive load, reduced burnout - Software Engineers
Clear production feedback without deep infrastructure guesswork - Platform & DevOps Teams
Systemic improvements instead of repeated firefighting - CTOs & IT Leaders
Lower MTTR and higher reliability — without scaling headcount
Together, these capabilities form an AI SRE Agent that can autonomously troubleshoot incidents in complex environments, correlate signals across systems, and propose actionable solutions in minutes instead of hours.
What’s Next
Starting next week:
- Day 1: Intelligent Investigation
- Day 2: Chat with the Investigation
- Day 3: Smart Slack
- Day 4: Enhanced Alerts View
One feature per day.
Real product workflows.
Built for how incidents actually happen.
Subscribe to our email newsletter and unlock access to members-only content and exclusive updates.
Comments