
The Problem: The Overwhelming Complexity of Modern IT
You've experienced it: a spinning loader wheel during online shopping right in the checkout page. For you, it's frustration! Behind the scenes, a team of technical experts is frantically searching for a single fault among millions of digital signals. Modern applications are incredibly complex; finding the cause of a slowdown is like looking for one faulty wire in an entire city's power grid.
The challenge multiplies in cloud-native environments. A single microservice failure in Kubernetes can cascade across dozens of dependent services, each generating its own alerts, logs, and metrics. Traditional troubleshooting - manually correlating logs, checking dashboards, tracing dependencies - can take 20 to 40 minutes just to understand what's broken, let alone fix it.
What if that team could find and even fix the problem before you ever noticed it?
Introducing AIOps: The Smart Supervisor for IT Operations
This is the promise of AIOps - Artificial Intelligence for IT Operations. It's a new approach that uses AI to instantly find the source of trouble, fundamentally shifting IT from reacting to failures to preventing them entirely.
But not all AIOps implementations are created equal. While traditional AIOps platforms focus on alert correlation and noise reduction, the next generation goes deeper - into autonomous investigation. Platforms like OpsWorker act as an AI SRE Agent, actively analyzing system behavior, examining logs across services, and surfacing explainable root causes with specific remediation steps, often completing investigations in under 2 minutes.
The goal for IT operations teams (ai operations) is a critical one: fewer incidents and faster recovery. AIOps helps them move from chaotic, reactive firefighting to steady, proactive control.
Who Are Digital Mechanics?
The team responsible for keeping your favorite apps and websites running smoothly 24/7 is IT Operations. They are the digital mechanics, ensuring reliability for customers. As technology scales, their control panel has gone from a few warning lights to an overwhelming storm of digital noise. This is why AIOps for IT teams is essential - it helps them pinpoint the critical problem in the chaos.
Supporting numerous developers and services—often hundreds of developers and dozens of services—with a small, centralized SRE team (typically 5 to 10 engineers) places immense pressure on those teams. The expectation to rapidly diagnose an issue, coordinate a solution, and communicate status during a 2 AM incident, all while being bombarded with continuous alerts, creates an unsustainable cognitive load. Intelligent automation is therefore essential to handle the initial investigation work and make this operational model viable.
Why 'Digital Noise' is Drowning Modern IT Teams
Imagine your car's dashboard replaced with ten thousand blinking lights. This is the reality for IT Ops. Every second, systems produce an avalanche of data - most of it harmless "digital noise," like a tire being a fraction of a degree too warm. Sifting through this manually to find a real problem is nearly impossible.
This constant flood causes a human problem: alert fatigue. Technical experts become desensitized to the endless stream of notifications, risking the chance that a truly critical warning - like a potential website crash - is missed. The goal is reducing IT alert fatigue so critical signals stand out.
Traditional IT monitoring no longer works at this scale. Teams don't need more data; they need instant meaning. AIOps monitoring augments traditional systems by correlating related events, suppressing duplicates, and surfacing probable root causes, allowing responders to act on what matters.
What is AIOps and How Does It Work?
If you're wondering what AIOps is, think of it as a brilliant supervisor for a company's digital mechanics. Instead of merely watching ten thousand lights blink, what an AIOps platform does is instantly recognize which combination of lights points to a real problem, using a vast memory of what's normal and what's not.
The true power of how AIOps works is its ability to connect the dots. It understands that a spike in customer complaints, a shopping cart slowdown, and a strange server error aren't three separate issues - they are all symptoms of one single root cause. It finds hidden patterns in the chaos, serving as one of the most powerful automated root cause analysis tools a company can have.
The most advanced implementations now go beyond pattern recognition into autonomous investigation. Platforms like OpsWorker, for instance, don't just correlate alerts - they actively investigate Kubernetes incidents by examining Application logs, Kubernetes Events, app traces, and other upstream, downstream dependencies in order to identifying root causes in approximately 2-5 minutes(depending on the complexity of the incident), which is very often before human responders even assemble. If we assume that the on-call person wakes up at night due to the PagerDuty or OpsGenie call, reads the alert on the phone, opens the laptop, logs in to the system, by that time, the on-call person should have already done all the root-cause investigation.
AIOps gives human experts a superpower. Instantly identifying the source of an issue, it frees talented engineers from stressful detective work, allowing them to focus on building a faster, more reliable solution.
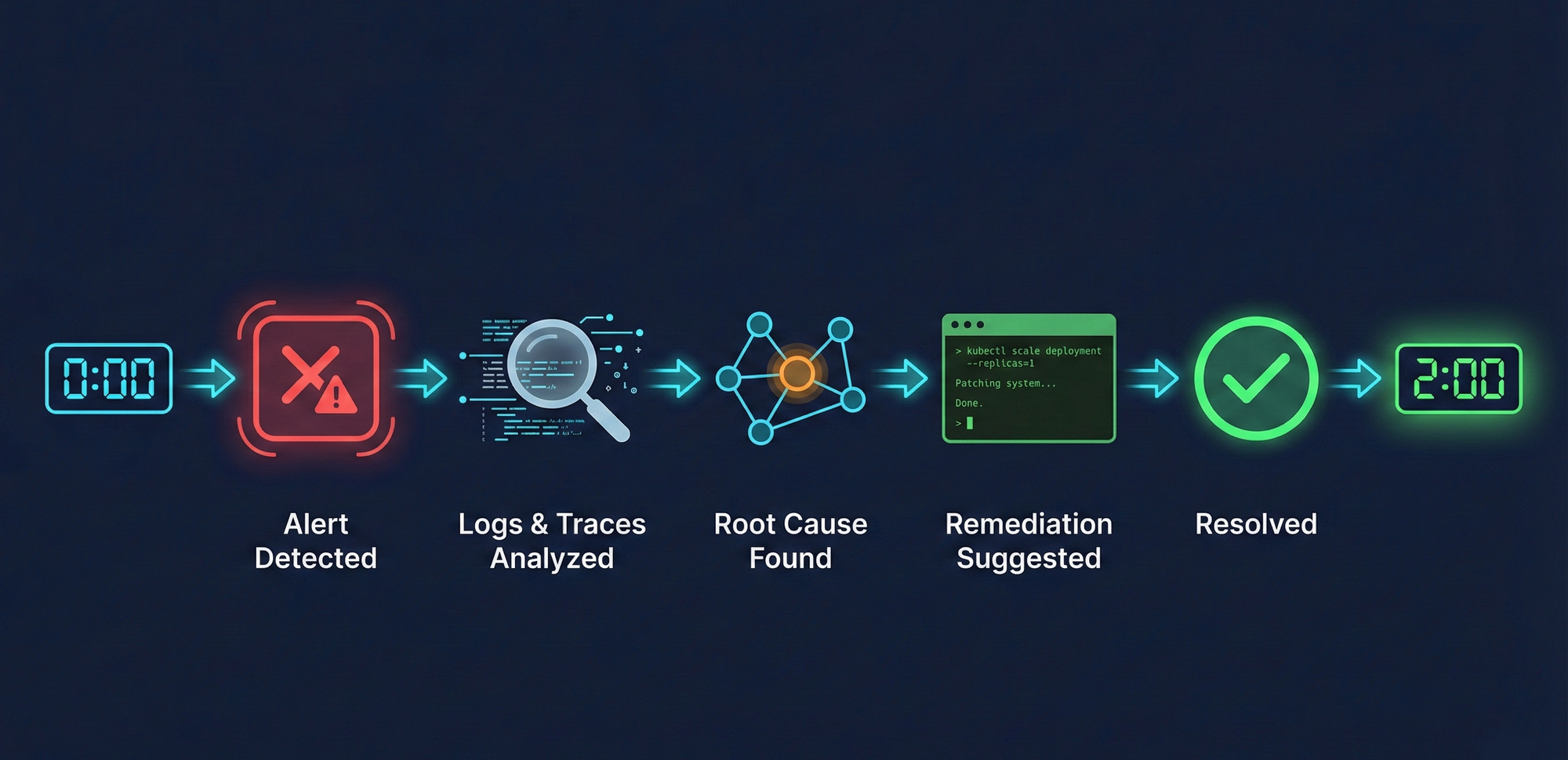
The AIOps Impact: From Reactive to Predictive
The real-world impact is clear:
This dynamic shift is thanks to the power of predictive analytics in IT operations. AIOps for incident management streamlines triage and routing, ensuring the right responders engage quickly. With ai incident automation, mean time to resolution is slashed, transforming the job of IT teams from firefighting to fire prevention.
What Are AIOps Solutions? The Real-World 'Toolbox'
AIOps solutions function as highly specialized, intelligent programs that serve as persistent, undetectable "supervisors" for your entire technology landscape. They are expertly designed to integrate fluidly with existing IT Operations tools, enhancing and streamlining workflows across observability, security, and service management to ensure your teams can manage operations efficiently and at massive scale.
These solutions come in two main flavors:
AIOps platforms: Complete, all-in-one toolboxes that handle everything from monitoring to analysis.
Specialized AIOps tools: Instruments that excel at one or two specific tasks.
Companies like Dynatrace, Datadog, and Splunk are well-known AIOps vendors- AIOps companies recognized for helping teams operate at scale. Analyst resources like the AIOps magic quadrant help teams compare vendors and shortlist the best AIOps tools. For security-focused environments, teams may prioritize the best AIOps for network security to correlate threat intelligence and reduce risk.
The Real Goal of AIOps: Building the Future
AIOps represents a strategic shift from reactive problem-solving to proactive prevention.
This shift enables Software Engineers, SREs or DevOps(owners of the applications, responsible for deploying and monitoring the workloads to production) to stop spending hundreds of hours per year on maintenance, troubleshooting, and catching up with all infrastructure changes but concentrate on producing the value. In the AIOps vs. SRE conversation, AIOps augments Site Reliability Engineering (SRE) practices by automating toil and providing richer context, so on-call engineers can focus on reliability engineering rather than repetitive tasks.
You're no longer just running infrastructure - you're engineering resilience at scale.
Subscribe to our email newsletter and unlock access to members-only content and exclusive updates.
Comments